 Uncensored AI models ➜ tools that run them ➜ break any model yourself ➜ all local, all free
Uncensored AI models ➜ tools that run them ➜ break any model yourself ➜ all local, all free
A model for every machine — phone to server farm — with the “I can’t help with that” ripped out. Offline, nothing logged. Plus the part nobody tells you: you can rip the refusal out of ANY model yourself, in one command.
Abliterated = the refusal reflex surgically cut out. Runs via Ollama (free app, one command) or Hugging Face. Everything below is free.

![]() Start here — plug in & go
Start here — plug in & go
Four that already come broken. New here? Pick one of these, run it, done.
🧠 Says yes to what others dodge — Huihui Qwen3.5 35B
Chinese devs huihui-ai, built on Qwen 3.5, refusals stripped. Goes where mainstream bots won’t.
ollama run huihui_ai/qwen3.5-abliterated:35b
![]() No guardrails = raw output. That’s the point.
No guardrails = raw output. That’s the point.
🔥 Eats whole codebases without forgetting — Gemini Heretic 40B
Barely refuses. 128K context (holds an entire book/long chat in memory). Coding, long writing, research. Shows its own reasoning as it works.
⚡ Killed the 'no' without going dumb — Gemma 4 12B Obliterated
First to hit 0 refusals, no benchmark loss. Most uncensored models get lobotomised — this one didn’t. 12B runs on modest/older hardware.
🏆 2,593 lines of code in one shot — Qwen3.5 21B Deckard
2,593 lines single-shot — ChatGPT taps out ~1,200–1,500. Holds logic across a full codebase, not snippets.
![]() Match it to your machine — phone to server farm
Match it to your machine — phone to server farm
The #1 question: “will it run on MY box?” Find your tier, grab the model. (VRAM = your graphics card’s memory.)
🪶 Phone / potato / CPU-only (≤4B)
Runs on a cheap laptop, an old GPU, even no GPU at all.
- huihui gemma3-abliterated 1B — one line:
ollama run huihui_ai/gemma3-abliterated:1b(~806 MB). A 270M tiny-tiny version exists too. - huihui Qwen3-4B-abliterated-v2 —
ollama run huihui_ai/qwen3-abliterated:4b(~2.5 GB). 0.6B & 1.7B also available. - DreamFast/qwen3-4b-heretic — 4B, near-perfect uncensor (0 damage score).
- mlabonne gemma-3-4b-it-abliterated — cleaner recipe, GGUF included.
- TheDrummer Gemmasutra-Mini-2B — 2B roleplay, has phone (ARM) builds.
🎒 Small daily driver (7–14B)
The sweet spot — runs on 8–12 GB and handles almost everything.
- huihui Huihui-Qwen3.5-9B-abliterated — 9B, one of the most-downloaded uncensored models going.
- huihui Qwen3 8B / 14B abliterated-v2 —
:8b/:14bon Ollama. - DreamFast/qwen3-8b-heretic — 8B Heretic, low damage.
- mlabonne NeuralDaredevil-8B-abliterated — the classic “healed” 8B (uncensored and still smart).
- Dolphin 3.0 Llama 3.1 8B —
ollama run dolphin3. You set the rules. - huihui phi-4-abliterated — 14B Phi-4, GGUF.
🖥️ Mid-tier muscle (20–40B)
Needs ~16–24 GB but punches hard.
- p-e-w gpt-oss-20b-heretic — the crowd favourite uncensor of OpenAI’s open model. Apache license.
- huihui / mlabonne gemma-3-27b-it-abliterated — 27B, can also see images.
- Dolphin 3.0 R1 Mistral 24B — uncensored reasoning model, shows its thinking.
- TheDrummer Cydonia 24B v4.3 — the reigning roleplay/creative king, 131K context.
- DavidAU Qwen3-42B TOTAL-RECALL Master-Coder — 42B, 256K context, coding beast.
🐉 Giant / server-class (70B → 754B)
For big rigs, multi-GPU, or Unsloth-shrunk on a single card (see the “GPU too small” section).
- huihui gpt-oss-120b abliterated — 120B.
- huihui DeepSeek-R1-Distill-Llama-70B-abliterated — 70B reasoning.
- huihui GLM-5.2 abliterated — 754B MoE flagship (MoE = only the needed slice runs, so it’s lighter than it sounds).
- huihui DeepSeek-671B / V4 abliterated — the 671B monster, uncensored.
- TheDrummer Behemoth 123B v2 — 123B creative powerhouse.
![]() Whatever model you already love — there’s a broken version
Whatever model you already love — there’s a broken version
Loyal to one base? Grab its unmuzzled twin. New bases get stripped within days of release.
🗂️ The family tree (pick your base)
- Llama 3.x / 4 → huihui Llama-3.3-70B-abliterated, NeuralDaredevil-8B
- Qwen 2.5 / 3 / 3.5 / 3.6 → the deepest bench, all at huihui-ai — incl. Qwen3.6-27B abliterated & Qwen2.5-Coder-14B-Abliterated
- Gemma 2 / 3 / 4 → mlabonne gemma-3 (1B→27B), p-e-w gemma-3-12b heretic
- Mistral / Nemo / Ministral → huihui Mistral-Nemo abliterated, mlabonne Mistral-Nemo-Prism-12B
- DeepSeek V3 / R1 / V4 → huihui R1-distills (8B/32B/70B) + the 671B
- Phi-4 → phi-4-abliterated, Phi-4-mini, Phi-4-multimodal
- GLM 4.x / 5.x → ArliAI GLM-4.6-Derestricted (clean method), Ex0bit GLM-4.7-PRISM, huihui GLM-5.2
- gpt-oss (OpenAI open) → p-e-w 20b-heretic, huihui 120b, DavidAU NEO-Imatrix builds
- Exotics → EXAONE, Granite, Hunyuan, InternVL, Qwen3-Omni — all abliterated in the huihui firehose
![]() The right unmuzzled model for the actual job
The right unmuzzled model for the actual job
👨💻 Coding without the 'I can't help with that'
- huihui Qwen3-Coder-Next abliterated — the top local coder, uncensored.
ollama run huihui_ai/qwen3-coder-next-abliterated - huihui Qwen3-Coder abliterated — scales huge (480B tag on Ollama for big rigs).
- Aesdi90 Qwen2.5-Coder-14B-Abliterated — fits a normal GPU.
- Dolphin 3.0 R1 Mistral 24B — reasons through hard bugs.
🎭 Roleplay / creative writing (the SillyTavern favourites)
The scene’s most-loved, 2026 picks:
- TheDrummer Cydonia 24B v4.3 + Anubis 70B, Behemoth 123B, Rocinante 12B — the daily drivers.
- Sao10K Stheno 8B, Euryale 70B, Lunaris 8B, Fimbulvetr 11B — legends of the genre.
- Midnight-Miqu 70B & Midnight-Rose 70B — the atmospheric classics.
- MythoMax-L2 13B — the OG that still gets downloaded daily.
Pair any of these with SillyTavern (in the frontends section) for characters + memory.
👁️ Vision — models that can SEE images, uncensored
- huihui Qwen3-VL-30B abliterated — flagship; also 8B & 32B sizes.
- prithivMLmods Qwen3-VL-8B-Abliterated-Caption — an uncensored image describer.
- huihui GLM-4.6V-Flash abliterated + Phi-4-multimodal abliterated.
🧩 Reasoning / 'thinking' models, unmuzzled
Models that work through problems step by step, with the brakes off.
- huihui QwQ-32B abliterated — strong open reasoner.
- Dolphin 3.0 R1 Mistral 24B — trained on 800k reasoning traces.
- huihui DeepSeek-R1-Distill-Qwen-32B abliterated — R1 brains, no refusals.
- DavidAU Brainstorm / TOTAL-RECALL builds — reasoning cranked up + huge context.
🛡️ Cybersecurity — a hacker's AI that won't flinch
Tuned on real security data, no “I can’t discuss that.”
- WhiteRabbitNeo V3 7B (aka DeepHat V1 7B — same model, rebranded at Black Hat 2025). Offensive + defensive.
- huihui Foundation-Sec-8B abliterated — Cisco’s security model, trained on 5.1B tokens of cyber data, then uncensored.
ollama run huihui_ai/foundation-sec-abliterated - huihui BaronLLM abliterated — offensive-security tuned.
ollama run huihui_ai/baronllm-abliterated - Dolphin3-Cyber 8B — OWASP + MITRE ATT&CK + CVEs baked in. Runs on a GTX 1650+.
- Lily-Cybersecurity 7B — 22k security Q&A, Mistral base.
![]() Follow the factory, not the file
Follow the factory, not the file
New model drops today? One of these has a stripped version by tomorrow. Bookmark the maker, never run dry.
📌 The people who break models for a living
- huihui-ai — the firehose. Hundreds of abliterations, updated ~weekly. Whatever drops, they strip it fast. Their
v2/v3releases beatv1. - Heretic org / p-e-w — automated, lowest-damage abliterations + the tool to DIY.
- DavidAU — Heretic + reasoning fusions + ready-to-run GGUFs.
- TheDrummer — roleplay/creative king (Cydonia, Anubis, Behemoth).
- Sao10K — Stheno, Euryale, Lunaris, Fimbulvetr.
- Cognitive Computations / dphn — the Dolphin line.
- mradermacher & bartowski — the two quant makers. If a model has no easy-run GGUF, search their pages — they’ve usually made it.
abliteratedandheretic— that’s 8,000+ and 4,000+ models right there. You’ll never run out.
🧪 Abliterated vs Heretic vs fine-tune — which do I want?
Three ways a model gets uncensored — pick the flavour:
- Abliterated — the refusal direction is cut from the weights. Fast, keeps the base’s brains, but can be a little “flat” until you push it with a firm instruction.
- Heretic — abliteration done automatically and tuned to keep the model smart (lowest brain-damage of the three). If a Heretic version exists, it’s usually the safest pick.
- Fine-tune (Dolphin-style) — retrained on open data. Most consistent and steerable, occasionally hallucinates a touch more.
Rule of thumb: Heretic > healed abliteration > raw abliteration for keeping quality. Still refusing? Move up a tier.
![]() The part they skip — don’t download it broken, break it yourself
The part they skip — don’t download it broken, break it yourself
A refusal is one direction inside the model. Find it, delete it. Works on ANY model — even next week’s release nobody’s stripped yet.
💥 One pip, any model, uncensored in ~45 min — Heretic
The big one. 7.9k stars, 1,000+ community models made with it. Point it at any model, it finds the refusal direction and removes it automatically — no ML knowledge, just a terminal.
pip install heretic-llm
heretic Qwen/Qwen3-4B
Runs unsupervised, keeps more of the model’s brains than most hand-made jobs. Save it, upload it, or chat right away. Pre-made ones live in its “The Bestiary” collection on HF.
🀄 The one built to kill Chinese-model censorship — llm-abliteration (DECCP)
From NousResearch. Originally made to strip censorship out of Chinese LLMs, runs the whole job in 4-bit shards under 8GB VRAM in ~2 minutes. Handles dense and mixture-of-experts models (the big MoE ones others choke on).
📓 The free Colab notebook that started it all — mlabonne's guide
Want to see the guts? Plain-English walkthrough + free Google Colab (runs in your browser, no GPU needed) that made abliteration a thing. Uncensor a model without owning any hardware.
![]() Zero-surgery mode — bend the model live, no file touched
Zero-surgery mode — bend the model live, no file touched
Instead of editing the model, shove a “be compliant” nudge into its brain as it thinks. Same file, dial it up or down like a slider.
🎚️ Type a mood, inject it as a dial — repeng (control vectors)
By Theia Vogel. Describe a direction in plain words (“uncensored,” “confident”) and it builds a control vector — a nudge added to the model’s activations at runtime. No retraining, no new weights. Export it and use it in llama.cpp with any quant.
📦 Pre-baked dials, ready to drop in — jukofyork/control-vectors
Don’t want to build your own? Grab ready-made control vectors in GGUF (the standard local-model format) and load them into llama.cpp with --control-vector. Stack several for layered effects.
![]() “My GPU’s too small” — says who?
“My GPU’s too small” — says who?
🐋 A 671B monster on a 24GB card — Unsloth Dynamic Quants
DeepSeek R1 is 671 billion parameters, normally 720GB. Unsloth’s trick: squeeze the useless layers to 1.58-bit, keep the important ones sharp → 131GB, an 80% cut, still writes working code. Runs on a single 24GB GPU (RTX 4090), or CPU-only with 20GB RAM if you’re patient.
📱 Chain your phone + laptop + PC into one brain — exo
The wild one. Model too big for any single device? exo splits it across all of them — phone, laptop, desktop, old Macs — peer-to-peer, no “main” machine. Your junk-drawer hardware pooled into one cluster that runs models none of them could alone.
💿 Run massive AI on a potato — AirLLM
Free library, 20k stars / 240k downloads. Reworks how models load so a 70B runs on a 4GB GPU, even 405B Llama 3.1 on 8GB VRAM. GPU, low-end, or CPU-only. Also does OCR (text out of images), image gen, assistants.

![]() Where you actually talk to them
Where you actually talk to them
The models are the engine. These are the dashboard — pick one, point it at a model, go.
🗲 One file, no install, runs on a 10-year-old PC — KoboldCpp
Single .exe — no Python, no Docker. Double-click, pick a model, chat. Broadest hardware support of anything (even integrated GPUs and ancient CPUs). Image gen + voice + transcription baked in. Remote Tunnel mode gives a link to reach it from anywhere.
📲 Run it at home, chat from your phone — LM Studio
Clean app to browse, download and compare models. The hidden gem: LM Link — your home GPU does the work, your phone is just the screen, over an encrypted tunnel. Full power on the couch. Built-in HF proxy for when Hugging Face is blocked where you are.
🎭 Characters, memory, lorebooks — SillyTavern
The roleplay/character frontend. Plugs into KoboldCpp, Ollama or LM Studio and adds character cards, long-term memory, world-info “lorebooks,” even live image gen. Where the uncensored models really come alive.
🪟 Fully offline, hybrid local + cloud — Jan
41k stars, 5.3M+ downloads. Runs 100% offline, flips to cloud models in the same window when you want. MCP support for agent workflows. The friendly all-rounder if KoboldCpp feels too raw.
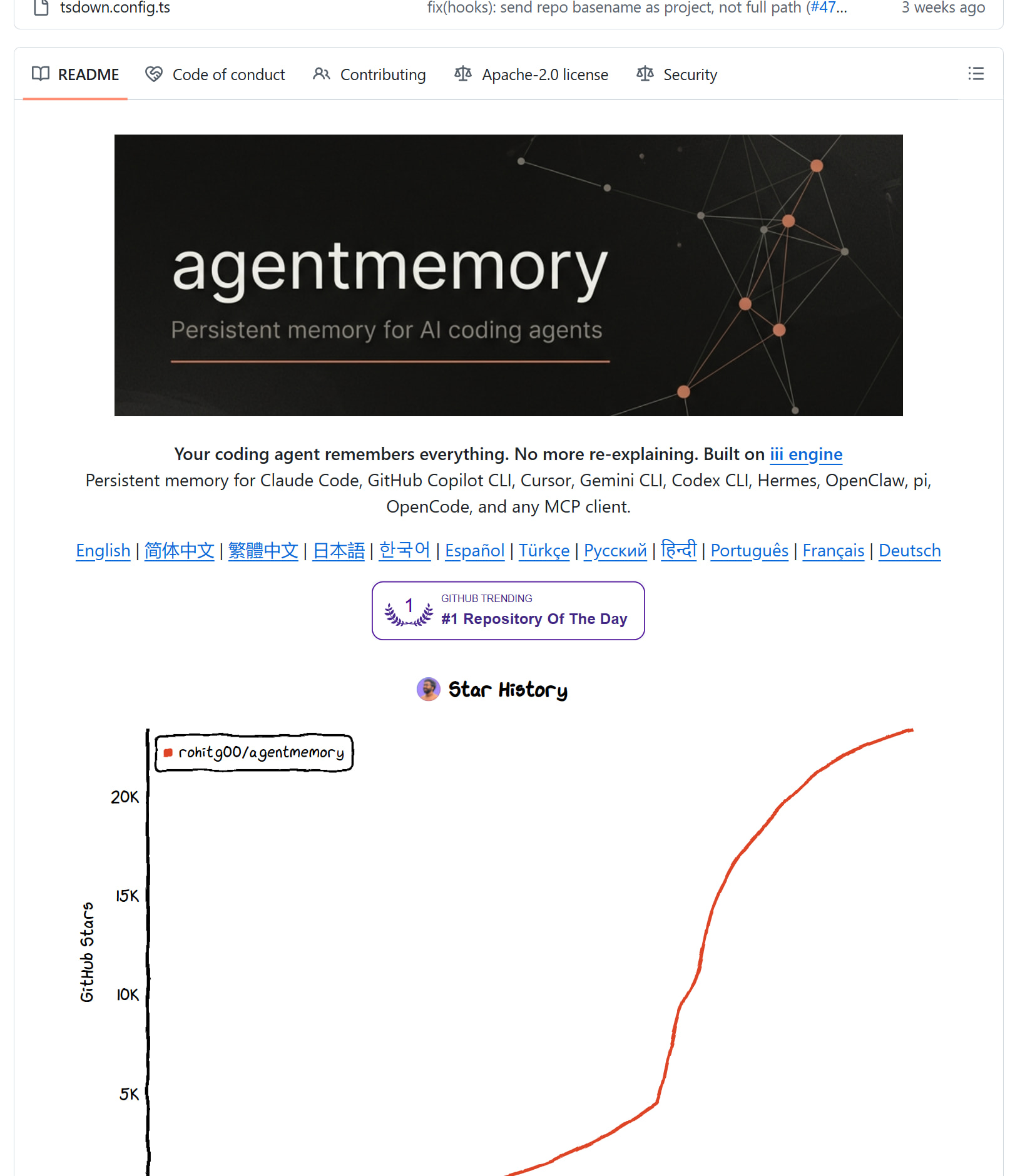
🧩 Bonus — give your AI a memory that sticks: AgentMemory
AI forgets on tab-close. This saves past chats, compresses them into structured memory, and pulls the right bits back. Remembers your project across sessions. #1 trending on GitHub. Plugs into Claude Code, Cursor, Codex, any MCP tool. Bonus: fewer re-sends = lower token cost.
![]() Where this actually bites in real life
Where this actually bites in real life
👀 The 'ohh shit, I could use this' list
 A hot new model drops with heavy censorship → run Heretic on it tonight, uncensored twin by morning. You don’t wait for anyone.
A hot new model drops with heavy censorship → run Heretic on it tonight, uncensored twin by morning. You don’t wait for anyone. Drop a 200-page contract or medical PDF in and ask blunt questions — nothing refused, nothing leaves your PC.
Drop a 200-page contract or medical PDF in and ask blunt questions — nothing refused, nothing leaves your PC. Generate a whole working app in one pass instead of babysitting 15 half-answers that keep hitting “I can’t.”
Generate a whole working app in one pass instead of babysitting 15 half-answers that keep hitting “I can’t.” A pentest write-up that lists real attack vectors — the security work cloud bots block as “harmful.”
A pentest write-up that lists real attack vectors — the security work cloud bots block as “harmful.” Zero cloud = your prompts never touch a company server, never train anything, never get your account nuked.
Zero cloud = your prompts never touch a company server, never train anything, never get your account nuked. Shrink a 671B beast down to the cheap card you already own instead of renting a GPU by the hour.
Shrink a 671B beast down to the cheap card you already own instead of renting a GPU by the hour. Your phone can’t run a 30B model — so let your home PC do it and just chat from the couch.
Your phone can’t run a 30B model — so let your home PC do it and just chat from the couch.
⚡ Pick fast (the cheat sheet)
 Potato PC → gemma3-abliterated 1B or a Dolphin 8B
Potato PC → gemma3-abliterated 1B or a Dolphin 8B 8–12 GB → Huihui Qwen3.5 9B or gpt-oss-20b-heretic
8–12 GB → Huihui Qwen3.5 9B or gpt-oss-20b-heretic 24 GB → Cydonia 24B (RP) or Dolphin R1 24B (reasoning)
24 GB → Cydonia 24B (RP) or Dolphin R1 24B (reasoning) Want ANY model uncensored → Heretic, one command
Want ANY model uncensored → Heretic, one command Don’t want to edit the model → repeng control vectors, live dial
Don’t want to edit the model → repeng control vectors, live dial Model too big → Unsloth quants, or exo across your devices
Model too big → Unsloth quants, or exo across your devices- Easiest front end → KoboldCpp (one file) or LM Studio (phone access)
 Weak machine + a giant model → it’ll crawl, drop a tier
Weak machine + a giant model → it’ll crawl, drop a tier
They ship the lock. Turns out it’s one line of code — and you’re holding the key. ![]()
 !
!