 The Free Tool That Strips AI Refusals Without Making the Model Dumber
The Free Tool That Strips AI Refusals Without Making the Model Dumber
Someone built a tool that strips the “I can’t help with that” out of any AI model. It’s called Heretic. It’s free. And it works.
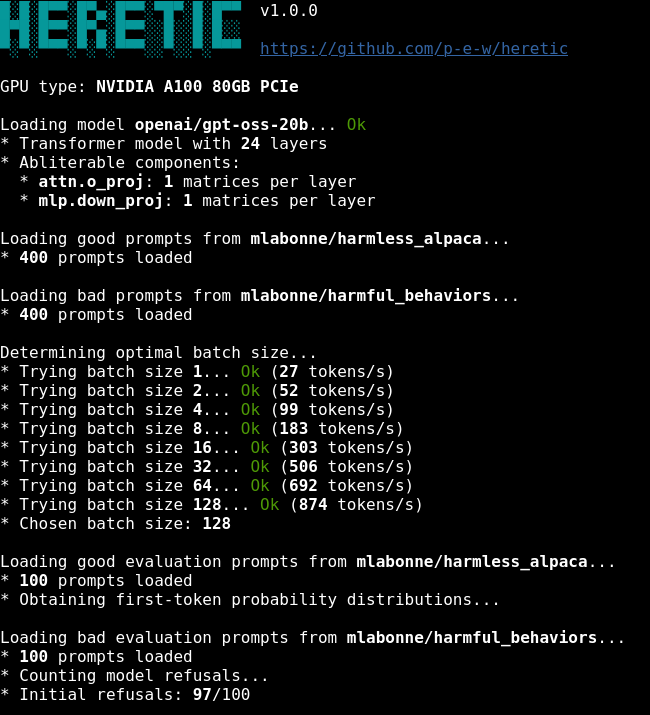
This exists. It’s on GitHub. It’s one command. Now you know.
Heretic finds the “no” button inside an AI model’s brain and gently turns it off — without making the model dumber. One command, ~45 minutes, fully automatic. 3,500+ GitHub stars. Over 1,000 community-made models already published.
🧠 What This Actually Does — Plain English, Zero Jargon
Think of an AI model like a very smart person who’s been told “never talk about certain topics.” The knowledge is still in there — they’ve just been trained to say “I can’t help with that” whenever those topics come up.
Heretic finds the exact part of the model’s brain responsible for saying “no” and surgically removes it — without touching the parts that make the model smart.
The cooking analogy: Imagine a chef who knows every recipe in the world but has been instructed to refuse making certain dishes. Heretic doesn’t make the chef forget recipes — it just removes the instruction that says “refuse.” The chef still knows everything. They just stop saying no.
What it does NOT do:
- It doesn’t add new knowledge to the model
- It doesn’t make the model “evil” — it just removes the refusal filter
- It doesn’t require you to understand how AI models work internally
What it DOES do:
- Removes the “I can’t help with that” responses
- Keeps the model’s intelligence intact (measured mathematically — more on that below)
- Works automatically — no manual tuning needed
⚙️ How It Works — The Process, Simplified
The technical name is “abliteration” — which sounds scary but the concept is simple.
Step 1 — Find the “no” direction
Heretic feeds the model two sets of prompts: harmless ones and ones that would trigger refusal. It compares how the model processes both and identifies the exact internal direction (think: a neural pathway) that causes refusal.
Step 2 — Remove that direction
Once found, Heretic mathematically weakens that specific pathway. Think of it as turning down the volume on a single speaker in a concert — the rest of the music (the model’s intelligence) keeps playing at full volume.
Step 3 — Optimize automatically
Here’s where Heretic is different from older tools. It doesn’t just remove the refusal and hope for the best. It runs an optimizer that finds the perfect balance between “stops refusing” and “stays smart.” It measures two things:
| Metric | What It Means |
|---|---|
| Refusal count | How many times the model still says “no” (lower = better) |
| KL divergence | How much the model’s responses changed from the original on normal topics (lower = less brain damage) |
The optimizer tries to minimize both — kill the refusals while keeping the model as close to its original intelligence as possible.
Step 4 — Save the new model
The output is a new model file you can use anywhere — locally, on Hugging Face, with any tool that runs AI models.
🛠️ How to Use It — The Actual Commands
Requirements:
- Python 3.10+
- PyTorch 2.2+
- A GPU with enough VRAM for the model you want to process (16GB handles most 4B-8B models)
The command:
pip install -U heretic-llm
heretic Qwen/Qwen3-4B-Instruct-2507
That’s it. Replace the model name with whatever model you want to uncensor. Heretic handles the rest automatically.
| Model Size | GPU Needed | Time |
|---|---|---|
| 4B params | ~8-16 GB VRAM | ~30 min |
| 8B params | ~16-24 GB VRAM | ~45 min |
| 12B params | ~24-48 GB VRAM | ~1-2 hours |
![]() No GPU? You can rent one. Google Colab (free tier has limited GPUs), or cloud GPU providers like RunPod and Vast.ai offer cheap hourly rates.
No GPU? You can rent one. Google Colab (free tier has limited GPUs), or cloud GPU providers like RunPod and Vast.ai offer cheap hourly rates.
📊 Does It Actually Work? — The Numbers
On Google’s Gemma-3-12b model, Heretic achieved the same refusal suppression as manually abliterated models — but with significantly less damage to the model’s intelligence:
| Model Version | Refusal Suppression | KL Divergence (brain damage) |
|---|---|---|
| Manual abliteration (expert) | 0.45 | |
| Another manual version | 1.04 | |
| Heretic (automatic) | 0.16 ← less damage |
Lower KL divergence = the model stays closer to its original intelligence. Heretic beats manual expert work — automatically.
Community feedback backs this up. Users report that Heretic-processed models give properly formatted, detailed responses without the “lobotomized” feel that older uncensoring methods produced.
🤔 Why Would Someone Want This?
| Use Case | Why |
|---|---|
| Creative writing | Censored models refuse to write violence, conflict, or mature themes — even in fiction |
| Research | Models refuse to discuss certain scientific, medical, or security topics in depth |
| Roleplay / storytelling | AI dungeon-style games need models that don’t break character to lecture you |
| Personal use | You downloaded an open model to run locally — you should be able to use it however you want |
| Anti-corporate filter | Some censorship isn’t safety — it’s brand protection and liability avoidance |
The key point: this only works on open-weight models you run yourself. It doesn’t affect ChatGPT, Claude, or any cloud API. You’re modifying a model you own, on your own hardware.
🔗 Resources
| Resource | Link |
|---|---|
| Heretic GitHub | github.com/p-e-w/heretic |
| PyPI (install) | pypi.org/project/heretic-llm |
| Pre-made Heretic models | Hugging Face search: “heretic” |
| Original abliteration paper | Arditi et al. 2024 |
| Optuna optimizer | optuna.org |
| Cheap cloud GPUs | RunPod · Vast.ai |
![]() Quick Hits
Quick Hits
| Want | Do |
|---|---|
→ pip install -U heretic-llm then heretic [model-name] |
|
| → Search “heretic” on Hugging Face | |
| → Rent one on RunPod or Vast.ai for ~$0.50/hr | |
| → Finds the “no” pathway in the model’s brain, surgically removes it, keeps everything else |
The smartest AI models already know everything. They’ve just been told to pretend they don’t. Heretic fixes that.
 !
!